We came to know from my previous post 'INTRODUCTION TO DATABASE-2' that data is present in tables in a database. For example, consider the following table which contains the department details in the AdventureWorks database(AdventureWorks is the default database added in the SQL SERVER which contains the data of a fictitious bicycle manufacturer, Adventure Works Cycles).

However, in order to store data in the database, we need to create our own database in which we create our tables and store our work.
CREATING AND USING DATABASE:
Use the following command to create a database, say 'sqlTutorials '.
CREATE DATABASE teachSqlServer;
The above command creates a database by the specified name. To use a particular database among all the databases present, one can use the following command.
USE teachSqlServer;
CREATING TABLES:
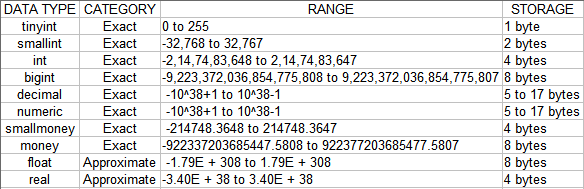
The information inside the database is organized into tables. While creating tables, we have to specify the name of the column, data type it holds and any constraints to be imposed on that column(we will get to know about constraints in the later sessions). A sample command is as follows:
CREATE TABLE prodType
(
productionTypeID TINYINT,
prodTypeName VARCHAR(15)
)
(
productionTypeID TINYINT,
prodTypeName VARCHAR(15)
)
NOTE:
SQL SERVER is not case sensitive i.e, create table is same as CREATE TABLE. However, to differentiate between user defined and predefined statements, names or commands, it is always better to follow certain standards. Some of the basic rules are;
- Use upper case letters for all the predefined commands, statements or names.
- In general, user defined naming conventions differ from one client to other but, it is advisable to follow a particular standard unless mentioned. Some of the common practices are:
- First letter of the words should be in uppercase with no spaces in between the words. Example: SqlServerTutorials
- First letters of all the words except the first word should be in uppercase with no spaces in between the words. Example: sqlServerTutorials
- All the letters in lowercase with the words separated by underscore between them. Example: sql_server_tutorials
In the next session, we will discuss regarding certain basic concepts which one needs to know before working with SQL-SERVER.